Many startups begin with one application and a hosted deployment service. That is usually the right decision. The team can ship without first building networking, deployment automation, or an operations layer.
The requirements change as the company adds services, environments, enterprise customers, private networking, and infrastructure ownership. The team still needs a short path to production, but the applications now need to run in infrastructure the company controls.
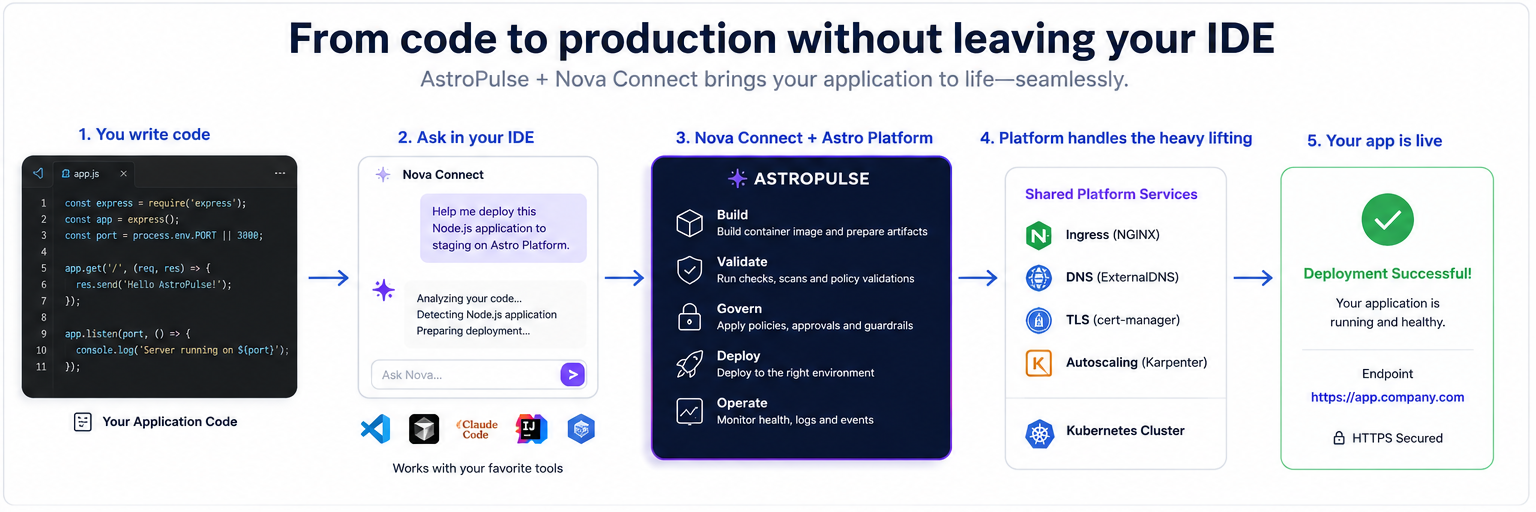
AstroPulse gives growing engineering teams a repeatable path from code to production in infrastructure they control, without requiring them to build the platform themselves.
From code in the editor to a healthy application, with one platform reused across multiple services.
When I started AstroPulse, the problem was easy to name and hard to live with: teams moving to the cloud were drowning in tools. Every provider had its own consoles, its own primitives, its own way to deploy an app and stand up a cluster. The work that mattered, shipping software, kept getting buried under the work of operating it.
I wanted one place to deploy an application and run a cluster, on any cloud, without learning five different platforms first. That was the beginning. Everything since has been built on top of that one idea, one layer at a time.
The AI SRE race will not be won by the agent that diagnoses fastest. It will be won by the system that operators trust enough to grant write access.
A personal note on where AI for operations is actually heading.
Over the past year a new category filled up fast. Depending on how you count, there are now more than a dozen credible tools that call themselves AI SREs. I have watched the space closely, partly because we are building in it, and partly because the speed of convergence is genuinely interesting.
Here is what nearly all of them do. They connect to your telemetry, your code, and your incident tooling. They correlate logs, metrics, and traces. When an alert fires, they form hypotheses, test them against the evidence, and post a likely root cause into Slack, often in under a minute. This is real progress. A few years ago none of it worked. Today most of it does.
Phase one is real
Diagnosis is real progress. But it is just phase one.
When something breaks in production at an odd hour, the person on call has to do three things at once: understand what is happening, decide what to do about it, and be able to explain all of it the next day. Most AI incident tools help with at most one of these. They either give you more data to read, or they take action you cannot see and cannot account for afterward.
We spent the last several months building Nova's investigation engine around that gap. This post is about how we designed it, the models we borrowed from, and the trade-offs we made along the way.
Every AI agent demo looks the same. The model calls a tool, gets a result, and responds. Then you run it against real infrastructure, and the demo falls apart in ways the tutorials never mention.
We have spent over a year building Nova, an AI agent that operates real infrastructure for real teams. It is not a chatbot that wraps API calls. It investigates incidents, executes remediations, and composes across dozens of integrations. This post is about what we learned: the problems that made us rebuild entire subsystems, and the patterns that survived.
Platform teams carry operational knowledge that does not transfer easily. The debugging instincts, the service interdependencies, the deployment quirks: they accumulate over years and live in a few people's heads. When those people are unavailable, the gap shows.
We built Nova to put that knowledge into a system you can query. This post covers what the architecture looks like and what we learned building AI that actually operates infrastructure.
Platform engineering represents the natural evolution of DevOps and SRE principles, but it faces a fundamental challenge: how do you scale platform expertise across an entire organization without requiring every developer to become a cloud expert?
This is where Nova comes in — your AI platform engineer that makes infrastructure accessible to everyone through natural conversation.
The Platform Engineering Evolution
DevOps broke down silos → SRE brought engineering rigor to operations → Platform Engineering created self-service infrastructure → Nova makes platform engineering conversational and accessible to everyone.
The Platform Engineering Challenge: Scale vs. Expertise
Platform engineering promised to solve the "you build it, you run it" scaling problem by creating Internal Developer Platforms (IDPs). But even the best platforms face fundamental limitations:
👥
Expert Bottlenecks
Platform teams become the new constraint—everyone depends on their expertise
📚
Documentation Decay
Complex systems require constant documentation that quickly becomes outdated
🧠
Context Loss
Critical operational knowledge lives in tribal knowledge, not systems
⚙️
Cognitive Load
Developers still need to understand infrastructure concepts to use platforms effectively
The Core Issue
We've built self-service platforms, but we haven't solved the underlying problem of democratizing platform engineering expertise.
Nova is an AI platform engineer that helps you manage infrastructure through natural conversation. Ask questions, get answers, generate configurations, and troubleshoot issues — all through simple chat.
What makes Nova different:
Works with your existing tools (Slack, GitHub, AWS, Terraform, Kubernetes, and more)
Available however you want to work — browser, self-hosted, or in your editor
Nova's power comes from its extensibility. Connect the tools you already use:
Available Skills:
Cloud Providers — AWS, Google Cloud, Azure cost calculations and resource management
Communication — Slack integration for team collaboration
Development — GitHub for code search, issues, and PRs
Infrastructure — Terraform and Helm configuration generation
Kubernetes — Cluster management and troubleshooting
And more — Add any MCP server for custom integrations
Bring Your Own Tools
Nova Direct includes the built-in MCP Marketplace for custom integrations. Nova Connect works through standard MCP-compatible clients, so teams can bring Nova into existing editor and CLI workflows without running the server locally.
The evolution from DevOps → SRE → Platform Engineering → AI-Assisted Platform Engineering represents more than technological progress — it's about democratizing expertise that has historically been scarce and expensive.
Traditional Model
Small teams of platform experts serve entire organizations