Building AI Infrastructure: The Case for Specialized Models and AI Agents

Building Enterprise AI Infrastructure: The Six Pillars, Specialized Models, and Emerging AI Agents
This deep-dive explores:
- The six pillars required (Data Infrastructure, GPU Infrastructure, Training Pipeline, Model Serving, Supporting Services, Security & Governance)
- Why specialized small models outperform foundation models for enterprises (85% better on domain tasks, 13-33x cheaper, data sovereignty)
- How emerging AI agents are changing economics (5-10 person platform teams → 1-2 engineers + AI agents)
- The open-source stack (KServe, vLLM, SGLang, TensorRT-LLM, MLflow, Kubeflow, DeepSpeed, Temporal)
- Why current tools are fragmented and operationally complex
- The vision: Self-hosted infrastructure with managed-platform simplicity—powered by specialized models for business logic + AI agents for operations
Introduction
Enterprises are discovering they can run powerful AI models on their own infrastructure—but building production AI infrastructure is significantly harder than application deployment.
This post breaks down the six interconnected systems required, why specialized small models outperform foundation models for enterprise use cases, how emerging AI agents are changing the economics, and the engineering trade-offs at every layer.

This is a comprehensive technical deep-dive. We explore the complete AI infrastructure landscape—from why enterprises build their own platforms to the six pillars required and the open-source technologies available.
- 🎯 Looking for specific topics? Use the navigation guide below to jump to what you need
- 📚 Want to understand the full picture? Read through—it's structured as a comprehensive exploration of AI infrastructure challenges and solutions
Navigation Guide
Everything you need is here—jump to any section:
The Small Model Revolution
Something exciting is happening in the AI world: enterprises are discovering they can run powerful AI infrastructure in their own cloud accounts or on-premise networks.
For years, teams assumed that deploying AI meant choosing between expensive API calls to hosted models or building complex infrastructure from scratch. But the landscape has changed dramatically.
Small, fine-tuned models outperform GPT-4 on specialized tasks (85% of domain-specific benchmarks). Fine-tuned Llama 3 8B can run 13x faster and 33x cheaper than GPT-4 while delivering higher accuracy for your specific domain. The secret is fine-tuning: training a model on YOUR data using techniques like LoRA achieves better results than generic foundation models.
This opens up an incredible opportunity for enterprises:
You can fine-tune models like Llama 3 8B or Mistral 7B on your proprietary data, deploy them on your own infrastructure—whether that's your AWS account, GCP project, Azure subscription, or on-premise network—and get better accuracy with lower latency while keeping your data completely under your control. You can run powerful AI workloads on standard GPUs without needing the most expensive hardware.
Train with specialized tools → Deploy to your infrastructure with one command → Own your data
This blog explores what it takes to build enterprise-grade AI infrastructure—and why, despite having all the open-source building blocks, it remains incredibly complex to assemble and operate at scale.
Why Enterprises Need AI Infrastructure
Data science teams across banks, hospitals, legal firms, and manufacturers are training custom models on proprietary data—fraud detection on financial records, diagnosis models on patient data, specialized case law understanding, sensor data from years of operations. Custom models trained on company-specific data outperform general-purpose models for specialized tasks.
Foundation models (GPT-4, Claude) excel at general tasks but struggle with enterprise economics: average enterprise AI spend was $7M in 2023, projected to grow 2-5x. At scale, per-token pricing becomes unsustainable, and data sovereignty requirements prevent sending proprietary data to external APIs.
The enterprise path: Fine-tune specialized small models on YOUR data (medical records, financial transactions, legal documents). Research shows fine-tuned 7-8B models outperform GPT-4 on 85% of domain-specific tasks while running 13-33x cheaper. Your competitive advantage comes from models trained on proprietary data, not access to the same GPT-4 everyone else uses.
Platforms like Hugging Face, Predibase, Together AI, and Modal make fine-tuning accessible. But many enterprises need something different: Run AI infrastructure in their own cloud accounts or on-premise networks, with complete control over where data lives and how infrastructure is managed.
Why Self-Hosted is Often Required
🏥 Compliance HIPAA (patient data in approved networks), SOX/PCI-DSS (financial audit trails), FedRAMP (government security)
🔒 Data Sovereignty Keep proprietary training data and inference within your network
⚡ Performance Lower latency than external APIs for real-time applications
💰 Economics At scale, owning infrastructure beats per-API-call pricing
🎯 Control Capacity, performance, availability, no vendor dependency
What Enterprises Actually Need
- 📊 Training
- 🚀 Deployment
- 📈 Management
- Train on proprietary data in their environment
- Ephemeral GPU provisioning for cost efficiency
- Distributed training automation (DeepSpeed/FSDP)
- Deploy to their GPU clusters (cloud or on-premise)
- Autoscaling for production workloads
- Multi-framework support
- Serve inference without data leaving their network
- Version and manage hundreds of models across teams
- Self-service for data science teams with GPU cost optimization
An internal AI platform with the simplicity of managed services, running on infrastructure you own—like internal developer platforms for applications.
The breakthrough: AI agents are beginning to handle the operational complexity that previously required large platform teams, making this practical for companies of all sizes.
What It Takes to Build AI Infrastructure (And Why It's So Hard)
Building AI infrastructure is not a technology problem—it's an architectural trade-offs problem.
The open-source technologies exist and work: KServe, Kubeflow, Kubernetes GPU scheduling, DeepSpeed. There's significant standardization work happening (CNCF projects, NVIDIA partnerships) and huge community backing. The talent pool that understands these technologies is growing. Building custom infrastructure in-house means reinventing solutions the community has already built and maintaining them yourself.
So Why Do Companies Struggle?
Because every architectural decision involves trade-offs—and traditional approaches require large platform teams to manage this complexity:
⚖️ Simplicity vs Flexibility Simple orchestration (easier) or Kubernetes (powerful but complex)?
💰 Cost vs Performance Optimize GPU utilization (complex) or developer velocity (wasteful)?
🤖 Automation vs Control Full automation (black box) or manual control (operational burden)?
Each choice has cascading effects across your entire platform. Historically, managing these trade-offs required 5-10 person platform teams. AI agents are beginning to change this—automating configuration decisions, debugging issues, and optimizing resources that previously needed human experts.
To understand these trade-offs, let's break down what you're actually building. An enterprise AI infrastructure platform isn't one system—it's six interconnected systems that must work together seamlessly. Understanding each pillar helps you make informed architectural decisions.
The Six Pillars of AI Infrastructure
An enterprise AI platform needs six core systems working together for both training and inference workloads.
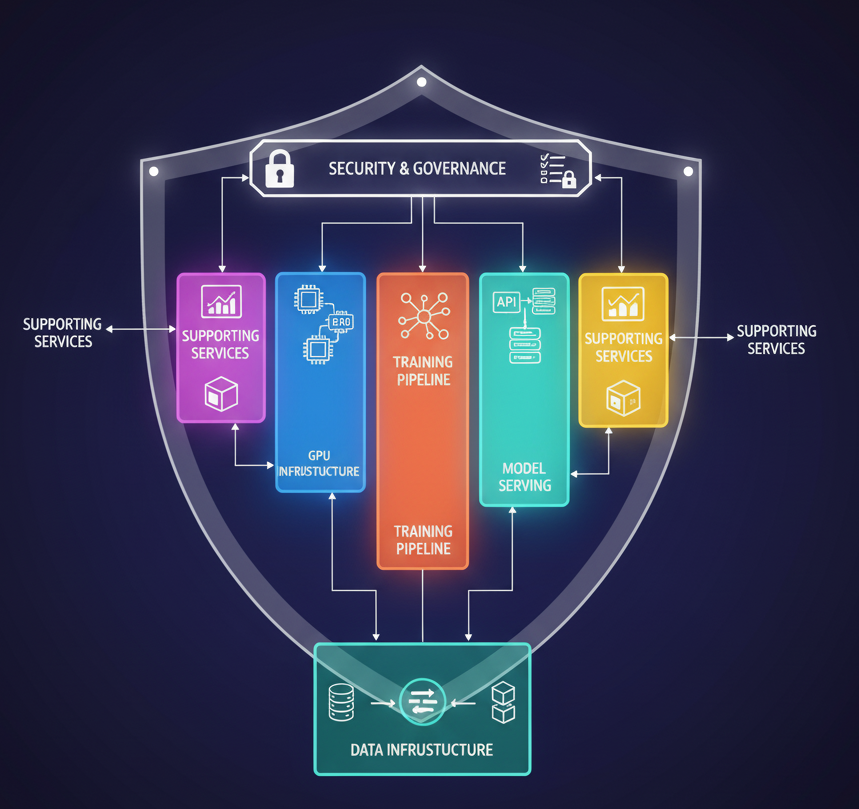
Here's the challenge: Each pillar is complex enough that entire companies and open-source projects focus on solving just ONE of them. Data infrastructure? Companies like Databricks, Confluent, and Apache Airflow. Model serving? KServe, vLLM all tackle different aspects. Security and governance? Entire platforms like Snyk, Cosign, and compliance frameworks. The real difficulty isn't solving one pillar—it's integrating all six to work together seamlessly while navigating architectural trade-offs at scale.
Let's explore each pillar and the technology landscape around it.
0. Data Infrastructure (The Hidden Foundation)
Before GPU clusters and model serving, you need clean, versioned, production-grade data.
This is where 50-70% of ML engineering effort goes.
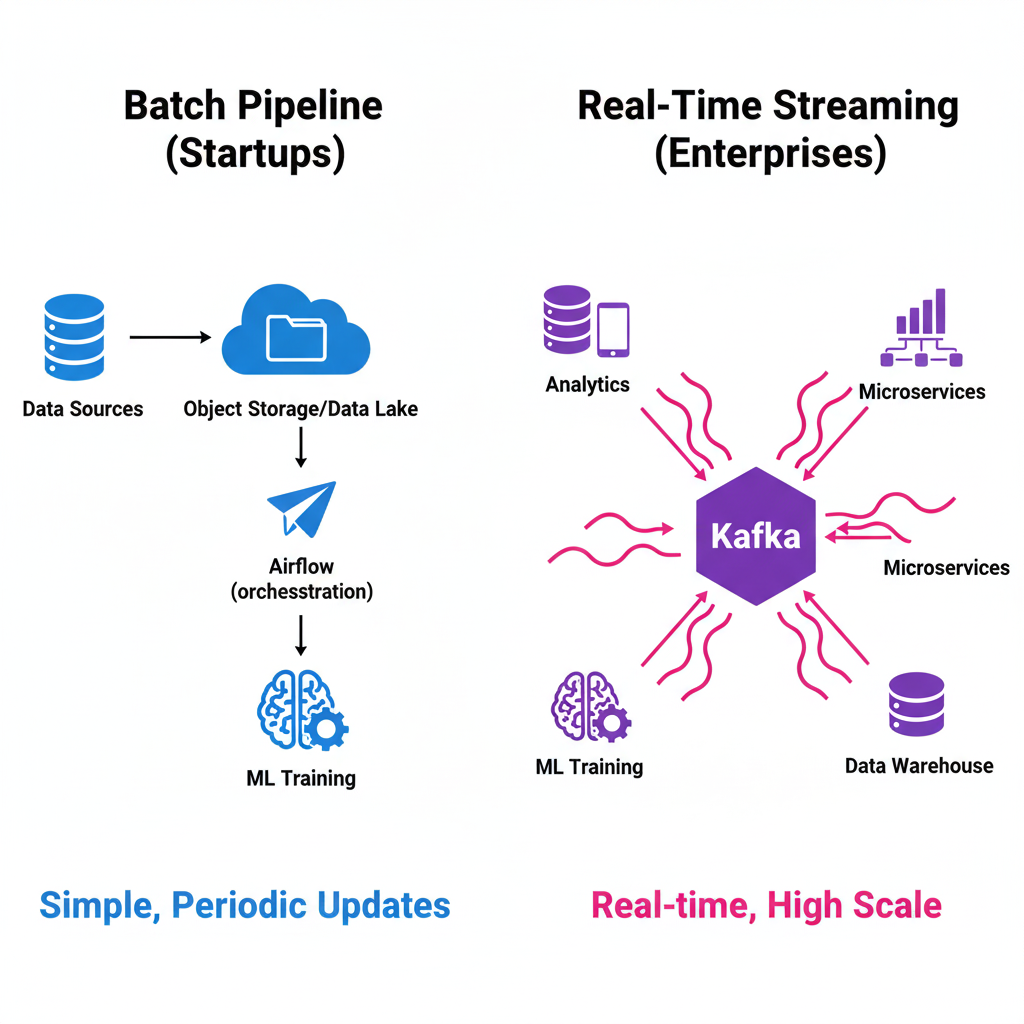
- 📦 Batch Pipeline (Most Startups)
- 🌊 Real-Time Streaming (Enterprises)
Architecture:
Data Sources → S3/Data Warehouse → Airflow (orchestration) → Training
Components:
- Data dumped to S3 or data warehouse (Snowflake, BigQuery)
- Apache Airflow schedules batch jobs (daily/weekly retraining)
- Alternative orchestrators: Dagster, Prefect
Best for: Periodic model updates, historical data analysis
Architecture:
Multiple Sources → Kafka (120+ connectors) → Multiple Consumers:
├─ Analytics
├─ Microservices
├─ Data Warehouse
└─ ML Training
Why Apache Kafka? Not for AI specifically—it's your company's data backbone:
- Schema Registry: Enforces data contracts (prevents breaking changes)
- 120+ connectors: No custom ETL code (databases, APIs, logs, files)
- Scales massively: Billions of events/day
Deployment options:
- Confluent Cloud (managed)
- Confluent for Kubernetes (Confluent operator)
- Strimzi (Apache Kafka on K8s, open-source)
- Redpanda (Kafka-compatible, simpler)
- Apache Pulsar (multi-tenancy)
Companies using Kafka already have it for analytics, microservices, and logs. AI just becomes another consumer of that data stream.
Don't build Kafka just for AI. If you're only doing ML training, S3 + Airflow is simpler and cheaper. Kafka makes sense when it serves multiple company-wide use cases.
❌ Can't reproduce training | ❌ Training-serving skew | ❌ Compliance failures
1. GPU Infrastructure (The Foundation)
GPUs are expensive and have different trade-offs than CPUs. The challenge exists for both training and inference.
- 🎓 Training
- ⚡ Inference
The Problem:
- Fine-tuning a Llama 3 8B model needs 8× A100 GPUs
- Most companies don't run training jobs 24/7
- But provisioning GPUs, setting up distributed training, and tearing down is complex
- You can't just "spin up 8 GPUs on demand" easily
The Trade-Off:
Unlike CPU instances that scale to zero easily, GPUs face a painful dilemma:
- Keep them running → Waste money on idle GPUs 💸
- Scale to zero → Face cold starts (loading multi-gigabyte model weights into GPU memory can take significant time; warm pools keep models resident for low-seconds P95, but first-load cold starts can be much higher) 🐌
The Financial Reality
GPU infrastructure represents one of the largest capital expenses for AI platforms (pricing as of October 2025*):
| GPU Type | Hardware Cost | Cloud Cost (On-Demand) | Cloud Cost (monthly, 24/7) |
|---|---|---|---|
| NVIDIA A100 (40GB) | ~$12,000-15,000 | ~$2.75-4/hour per GPU** | ~$2,000-2,900/month per GPU |
| NVIDIA H100 (80GB) | ~$25,000-30,000 | ~$12-14/hour per GPU** | ~$8,600-10,000/month per GPU |
| 8× A100 (40GB) cluster | ~$96,000-120,000 | ~$32.77/hour (AWS p4d.24xlarge)** | ~$23,600/month |
** On-demand pricing shown. Reserved instances (AWS), committed use discounts (GCP), and reserved capacity (Azure) can reduce costs by 30-70% with 1-3 year commitments. Spot/preemptible instances offer deeper discounts but can be interrupted.
For a modest enterprise AI platform with 10 GPUs running 24/7 (on-demand pricing):
- Hardware: $150,000-400,000 upfront
- Cloud (on-demand): $120,000-250,000/year
- Cloud (reserved/committed): $40,000-120,000/year (with 1-3 year commitment)
The ROI of GPU Optimization
At scale, even 20% GPU utilization improvement saves $24,000-50,000 annually.
The math for a single H100 GPU (October 2025 pricing):
| Metric | Value |
|---|---|
| On-demand cost | ~$12-14/hour per GPU |
| Reserved (1-year) | ~$8-10/hour per GPU (30-40% discount) |
| Annual runtime | 8,760 hours |
| Cost per GPU/year (on-demand) | ~$105,000-122,600 |
| Cost per GPU/year (reserved) | ~$70,000-87,600 |
20% utilization improvement (50% → 70%) with reserved instances:
- Baseline (50% util): $140,000-175,000/year for 1 GPU's worth of work
- Improved (70% util): $100,000-125,000/year for same work
- Savings per GPU: $40,000-50,000/year
For a 10-GPU cluster: $400,000-500,000 annual savings 💰
This is why software that maximizes GPU utilization isn't just about performance—it's about making AI infrastructure financially sustainable. Features like fractional GPU sharing, intelligent auto-scaling, and cold start optimization directly translate to cost savings that justify platform investment.
What You Actually Need:
GPU Node Pools
Different workloads need different GPUs: smaller GPUs for inference, larger for training. Mix and match based on workload.
Fractional Allocation
Run multiple small models on 1 GPU instead of separate GPUs. Significant cost savings.
Dynamic Scaling
Scale to zero for batch jobs, keep warm pools for real-time inference. Optimize for cost AND latency.
Driver Management
CUDA versions, cuDNN libraries, GPU drivers - all must match exactly. One mismatch breaks everything.
GPU Monitoring & Observability
Track utilization, memory, temperature, and failures. GPU clusters have distinct failure modes (hardware, NVLink, driver issues) requiring DCGM-level monitoring.
Advanced Considerations (As You Scale):
While the features above address the core GPU infrastructure needs, larger enterprises may eventually need additional capabilities. Multi-tenancy with resource quotas becomes important when multiple teams share GPU clusters and need isolation and fair resource allocation. Topology-aware scheduling optimizes placement for multi-GPU distributed training jobs by leveraging high-bandwidth NVLink connections (4-10x faster than PCIe). However, these add significant complexity and operational overhead—only invest in them when the cost savings justify the engineering effort.
GPU Infrastructure Orchestration: Choosing the Right Approach
Building AI infrastructure means choosing an orchestration layer to automate GPU resource management, deployment, and scaling. Here are the options available today:
| Orchestration Layer | What It Provides | Best For |
|---|---|---|
| IaC + Config Management (Terraform/Pulumi + Ansible) | Automated provisioning & configuration | Fixed GPU clusters, predictable workloads |
| Container Orchestration (Nomad, Docker Swarm, AWS ECS) | Basic scheduling, health checks, service discovery | Simpler than K8s, good for small-medium scale |
| Kubernetes (Kubernetes + KServe) | Advanced scheduling, autoscaling, GPU-aware scheduling, multi-tenancy | Multiple teams, dynamic workloads, GPU sharing needs |
| Cloud Managed Services (AWS SageMaker, GCP Vertex AI, Azure ML) | Fully managed by cloud provider, integrated with cloud services | Running on cloud infrastructure, want managed operations |
How to decide?
The key question is: How much automation do you need?
- IaC tools automate provisioning but deployments/updates are still manual workflows
- Simple orchestrators add health checks, rolling updates, basic scaling
- Kubernetes provides full automation—GPU scheduling, autoscaling, multi-model serving—but adds significant complexity
- Cloud managed services handle everything but reduce control and create cloud provider lock-in
In practice: When you run astroctl ai model deploy s3://my-model/, the platform analyzes your requirements (traffic, latency, budget) and automatically picks the best orchestration approach (existing K8s cluster, new ECS cluster, or cloud managed service like SageMaker). Advanced users can override with flags like --orchestrator kubernetes or --orchestrator sagemaker if they know their preference upfront.
Current State (What's Available Today):
For GPU management within these orchestration layers, the open-source ecosystem provides:
- NVIDIA GPU Operator: Automates GPU driver installation, device plugins, and monitoring in Kubernetes
- Volcano: Open-source batch scheduler for Kubernetes with gang scheduling for distributed training
- NVIDIA k8s-device-plugin: Enables GPU discovery and allocation in Kubernetes
- Cloud provider tools: AWS EKS GPU support, GCP GKE GPU node pools, Azure AKS GPU instances
The challenge: These open-source tools exist but require significant expertise to configure correctly. Driver versioning, CUDA compatibility, and GPU sharing are complex operational problems.
2. Training Pipeline (Building Models)
A training pipeline is the end-to-end system for taking your raw data and turning it into a trained model ready for production. It's not just running model.fit()—it's the entire infrastructure that provisions GPUs, loads data at scale, distributes training across multiple GPUs, handles failures, saves checkpoints, and tracks costs.
Why is this important?
Training custom models on your proprietary data is what gives you competitive advantage. Pre-trained models are excellent starting points, but fine-tuning on your specific data (customer support tickets, medical records, financial transactions, legal documents) is what makes models truly valuable for your business.
Training large models requires expensive multi-GPU infrastructure that most companies run infrequently. You might train a model once a week or once a month—but provisioning, configuring, and tearing down distributed GPU clusters for each training job is complex and time-consuming.
- ✨ The Vision
- 😓 The Reality
What data scientists would prefer:💡 Click to see example: One command to train a model
What actually happens without a platform:
- Provision 8× A100 GPUs manually (AWS console, GCP console, Terraform)
- Set up distributed training (DeepSpeed/FSDP configuration)
- Configure data loading from S3 with credentials
- Set up checkpointing (save every N steps to S3)
- Monitor training progress (TensorBoard, MLflow setup)
- Handle failures and restarts (manual checkpoint recovery)
- Release GPUs when done (remember to terminate instances!)
- For experienced platform engineer: Days to set up
- For data scientist: Weeks of frustration
- Cost: Thousands wasted on idle GPUs 💸
There's no unified platform for "train on your data → deploy from storage → monitor at scale." You're stitching together 5+ different tools and hoping they work together.
What a Real Platform Needs:
For Training:
- Ephemeral GPU provisioning: Request GPUs for training job, auto-release when done
- Distributed training automation: DeepSpeed/FSDP configured automatically based on model size
- Training orchestration: Ray Train or Kubeflow Training Operator to manage multi-GPU jobs at scale
- Data loading from storage: S3/GCS credentials managed securely
- Checkpoint management: Auto-save to S3, resume from last checkpoint on failure
- Cost tracking: Real-time cost burn, alerts when budget exceeded
Distributed Training Technologies:
| Technology | What It Does | When to Use |
|---|---|---|
| DeepSpeed/FSDP | Memory-efficient model sharding across GPUs (the actual parallelism strategy) | Large models that don't fit on single GPU |
| Ray Train | Orchestration layer that runs DeepSpeed/FSDP jobs across GPU clusters | When you need to scale training jobs across multiple nodes |
| Kubeflow Training Operator | Kubernetes-native training job management (PyTorch, TensorFlow, XGBoost) | When you're running on Kubernetes and want native integration |
Key insight: DeepSpeed/FSDP handle how to split models across GPUs. Ray Train/Kubeflow handle where to run those jobs at scale. You often use them together—Ray Train orchestrates DeepSpeed jobs across your cluster.
Complete ML Lifecycle: Kubeflow + KServe
For enterprises running on Kubernetes, Kubeflow provides an end-to-end ML platform:
- Kubeflow Pipelines: Orchestrate multi-step ML workflows (data prep → training → validation → deployment)
- Kubeflow Training Operator: Manage distributed training jobs (PyTorch, TensorFlow, XGBoost, MPI)
- KServe: Production model serving with autoscaling, canary deployments, A/B testing
The power of this stack is integration: train a model with Kubeflow Training Operator, store it in your model registry, and deploy to KServe for inference—all within the same platform. This is the closest open-source equivalent to cloud-managed services (SageMaker, Vertex AI) but running on your own Kubernetes infrastructure.
Trade-off: Kubeflow is powerful but complex. It requires Kubernetes expertise and significant setup/maintenance effort. For simpler use cases, standalone tools (Ray Train for training, standalone KServe for serving) may be easier to start with.
3. Model Serving Framework (The Brain)
Model serving is the infrastructure that exposes your trained models as production APIs that applications can call. It's not just loading a model into memory—it's the entire system that handles API requests, batches them efficiently for GPU processing, autoscales based on traffic, and manages deployments without downtime.
Why is this important?
Your models are only valuable if applications can actually use them. A customer support chatbot, fraud detection system, or document analysis tool needs to call your model APIs in real-time—with low latency, high reliability, and predictable costs. Model serving is what makes AI models accessible to your applications.
Serving models efficiently on GPUs is hard. Unlike stateless web services that scale easily, GPU-based models require loading multi-gigabyte weights into memory, batching requests for efficiency, and managing expensive GPU resources that you can't afford to waste but also can't afford to be slow.
- ✨ The Vision
- 😓 The Reality
What developers would prefer:💡 Click to see example: One command to deploy a model
What actually happens without a platform:
- Choose a serving framework (KServe, vLLM, Triton)
- Write Kubernetes manifests (deployment, service, ingress, HPA)
- Configure GPU resource limits and node affinity
- Set up model loading from S3 with credentials
- Configure autoscaling rules (scale to zero, warm pools, request queue depth)
- Build API gateway with authentication and rate limiting
- Set up monitoring (latency P95/P99, GPU utilization, error rates)
- Test canary deployments and rollback procedures
- Setup time: Weeks for each model serving setup
- Ongoing issues: Debug cold starts, GPU OOM errors, scaling issues
There's no simple "deploy model to API" solution. You're choosing between complex orchestration (KServe on K8s) or cloud lock-in (SageMaker/Vertex AI).
How Applications Talk to Models
Most AI platforms expose models through OpenAI-compatible REST APIs:
curl https://your-platform.com/v1/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "llama-3-8b-custom",
"messages": [{"role": "user", "content": "Analyze this..."}]
}'
Most AI SDKs (LangChain, LlamaIndex, Vercel AI SDK) support this format. Swap OpenAI's GPT-4 with your custom model by just changing the endpoint—zero code changes.
Popular Open-Source Technologies:
| Technology | What It Does | When to Use |
|---|---|---|
| KServe | Kubernetes-native serving platform (autoscaling, canary deployments, multi-framework) | Running on K8s, need production GitOps workflows |
| vLLM | High-performance LLM inference engine (PagedAttention, continuous batching) | Serving transformers/LLMs with max throughput, excellent balance of performance and ease of use |
| SGLang | Fast inference engine with RadixAttention for structured generation and multi-turn conversations | Complex prompting workflows, structured outputs, agentic applications with state management |
| TensorRT-LLM | NVIDIA's optimized LLM inference engine (graph optimization, kernel fusion, FP8 quantization) | Maximum performance on NVIDIA GPUs, latency-critical applications, willing to invest in optimization |
| Triton Inference Server | NVIDIA multi-framework server (TensorFlow, PyTorch, ONNX, TensorRT-LLM backend) | Non-LLM models, multi-framework deployments, NVIDIA-optimized runtimes |
How they work together: KServe orchestrates (manages deployments, scaling, routing), while vLLM/SGLang/TensorRT-LLM/Triton are inference engines (run models efficiently).
Choosing an inference engine:
- vLLM: Best starting point for most LLM deployments - excellent performance, easy to use, wide model support
- SGLang: Choose when you need advanced features like RadixAttention for caching multi-turn conversations or structured generation
- TensorRT-LLM: Maximum performance on NVIDIA GPUs, but requires more setup and optimization effort - best when latency is critical
- Triton: Use when serving multiple model types (not just LLMs) or need NVIDIA's enterprise support
Performance Optimizations:
Model serving runtimes use these techniques to serve models faster with less GPU memory:
| Optimization | What It Does | Impact |
|---|---|---|
| Quantization | Reduce model precision (FP16 → INT8/INT4) | 2-4× faster inference, 50-75% less memory |
| PagedAttention (vLLM) | Efficient KV cache management inspired by virtual memory | 2× throughput improvement |
| Continuous Batching | Process requests as they arrive, not fixed batches | Higher GPU utilization, lower latency |
| Speculative Decoding | Small model predicts tokens, large model verifies | 2-3× faster generation |
| Flash Attention | Optimized attention kernel implementation | 3× faster, reduced memory |
Real-world impact: Llama 3 70B requires ~140GB GPU memory (FP16). With INT4 quantization (GPTQ/AWQ), model weights compress to ~35GB, though KV cache and runtime overhead can push total VRAM requirements higher during inference—still a significant reduction enabling smaller GPU configurations.
4. Supporting Services (The Plumbing)
The serving framework is just the beginning. Around it, you need an entire ecosystem:
Core Supporting Services:
The operational foundation for production AI systems:
| Service | What You Need | Popular Open-Source Tools |
|---|---|---|
| Model Registry | Object storage (S3/GCS) for model artifacts + metadata DB (PostgreSQL/MongoDB) for version history, lineage, performance metrics | MLflow, S3/GCS + PostgreSQL |
| API Gateway | Authentication (API keys, OAuth, mTLS), rate limiting, request logging, canary deployments | Kong, Envoy, Traefik |
| Monitoring | Inference latency (P50, P95, P99), GPU utilization, model drift detection | Prometheus + Grafana, MLflow Tracing |
| Cost Tracking | GPU hours per team/namespace, inference cost per model, per-user API usage, storage costs | Kubecost (K8s), custom metering |
Usage-Based Billing & Cost Attribution:
At scale, you need to track who's spending what on GPU infrastructure:
- GPU hours per team/namespace: Chargeback training costs to departments
- Inference cost per model: Tokens processed × GPU time
- Per-user API usage: Bill internal teams or external customers
- Storage costs: Model weights, datasets, checkpoints by project
Without this, a $20k/month AI bill has zero visibility into which teams or models are driving costs.
Workflow Orchestration:
Behind every model deployment is a complex sequence of steps that must execute reliably: validate the model, provision resources, build containers, deploy to the cluster, wait for readiness, register monitoring. Traditional bash scripts fail midway and leave infrastructure in unknown states. You need durable workflow orchestration:
| Capability | What You Need | Popular Open-Source Tools |
|---|---|---|
| Long-running operations | Handle cluster provisioning (30+ minutes) without timeouts | Temporal, Argo Workflows |
| Automatic retries | Retry transient failures with exponential backoff | Temporal, Apache Airflow |
| Durable execution | If orchestrator crashes, workflows resume exactly where they left off | Temporal |
| Human approvals | Wait for cost/compliance approvals with configurable timeouts | Temporal, Argo Workflows |
5. Security, Compliance & Governance (The Shield)
Enterprise AI platforms must address security threats, meet regulatory requirements, and implement financial controls.
Security Threats (OWASP Top 10 for LLMs 2025):
- Prompt Injection: Malicious inputs manipulating model behavior
- Sensitive Information Disclosure: Unintended exposure of training data
- Data Poisoning: Malicious manipulation of training data or weights
- Supply Chain Vulnerabilities: Compromised components or dependencies
Supply Chain Security Tools:
AI models have complex dependencies (container images, Python packages, CUDA libraries, model weights). Verify and track what you're deploying:
| Security Layer | What It Does | Popular Open-Source Tools |
|---|---|---|
| SBOM Generation | Complete inventory of all components (container images, Python packages, CUDA libraries, model weights) | Syft, SPDX |
| Vulnerability Scanning | Scan for CVEs before deployment | Trivy, Grype |
| Image Signing | Cryptographic verification of container images | Cosign |
| Registry Allowlisting | Only deploy from approved sources | Policy enforcement in K8s |
Compliance Requirements:
Meet regulatory requirements for AI systems:
| Regulation | Requirements | Platform Needs |
|---|---|---|
| EU AI Act (High-risk systems: Aug 2, 2026) | Automatic logging, quality management, annual audits | Audit trails, version control, data lineage |
| HIPAA Security Rule | Administrative, physical, technical safeguards; BAAs; audit trails | Access controls (RBAC), encryption, audit logs |
| SOC 2 for AI | Version control, data lineage, explainability, bias detection | Model registry, monitoring, bias detection tools |
Financial Governance (Cost Approval Gates):
Without controls, teams can accidentally spin up thousands in monthly GPU costs. Leading platforms implement:
- Estimate before deploy - Generate cost breakdown (compute, storage, networking)
- Explicit approval - Users approve monthly estimates
- Policy-based thresholds - Auto-approve under limits, escalate above
- Plan integrity - Cryptographically signed estimates (HSM-backed)
- Audit trail - Record who approved, when, estimate amounts
Example:
$ astroctl ai model deploy s3://my-bucket/my-llm/
🤖 Nova analyzing model...
📊 Recommended: 2× A10 GPUs on your EKS cluster, serverless scaling
💰 Estimated cost: $891/month
GPU: $600 | EKS: $73 | LB: $18 | Storage: $100 | Net: $100
⚠️ Approve $891/month? [Y/n]: Y
✅ Deployment approved. Proceeding...
Alerts trigger when actual costs deviate >10% from estimates.
Why Companies Choose Managed vs. Self-Hosted
Each of these six pillars requires significant engineering effort. Understanding this explains why companies make different choices.
The Engineering Challenges:
Each of the six pillars presents significant complexity:
- Data Infrastructure: Data versioning, lineage tracking, data quality validation, pipeline orchestration
- GPU Infrastructure: Multi-cloud provisioning, driver version management, node pool optimization, per-workload cost tracking
- Training Pipeline: Distributed training orchestration (DeepSpeed/FSDP), checkpoint management, data loading from object storage, failure recovery
- Model Serving: Model loading from storage with credentials, autoscaling for GPUs, multi-framework support, A/B testing, rollback
- Supporting Services: Model registry, API gateway, monitoring, cost tracking, workflow orchestration
- Security & Governance: Supply chain security, vulnerability scanning, compliance (EU AI Act, HIPAA, SOC 2), cost approval gates
Plus ongoing operations: On-call coverage, security patches, supporting new GPU types (H100, H200, GB200), framework updates, compliance audits, continuous cost optimization.
This operational burden is why managed platforms exist—they abstract away complexity but at the cost of data sovereignty and control.
Why Managed Platforms (Fireworks, Together, Baseten)?
- No platform engineering required
- Immediate access (minutes vs. months)
- Latest GPU types and optimizations
- Pay-per-use pricing
Trade-off: Data leaves your infrastructure, limited customization, per-token costs.
How AI agents change this: Early agents (Devin, Sweep) already handle SRE debugging, infrastructure-as-code generation, and deployment automation. For AI infrastructure, agents can configure distributed training (DeepSpeed/FSDP), debug GPU issues (CPU fallback detection), optimize costs (right-sizing GPUs)—reducing the 5-10 person platform team to 1-2 engineers + agents.
Why Self-Hosted?
- Data sovereignty: Healthcare (HIPAA - patient data can't leave approved networks), Finance (SOX, PCI-DSS), Government (FedRAMP, classified data)
- Proprietary training data: Frequent fine-tuning on sensitive internal data that cannot be sent externally
- Scale: At massive token volumes, infrastructure costs can be more favorable
- Custom requirements: Air-gapped environments, on-premise datacenters, regional data residency (GDPR, data localization laws)
- Control: Own the full stack, customize workflows, no vendor dependency
The choice depends on: Data sensitivity and regulatory requirements, scale, engineering capacity, and timeline. Both paths are valid—managed platforms abstract the complexity, self-hosted gives complete control.
Cloud-Managed Services (The Middle Ground):
For teams that need data sovereignty but don't want to manage raw infrastructure, cloud-managed AI services offer a hybrid option:
| Service | Provider | Best For | Data Stays in Your VPC? | Custom Models? |
|---|---|---|---|---|
| AWS SageMaker | AWS | Training + Inference on AWS | ✅ Yes (within AWS) | ✅ Custom containers supported |
| AWS Bedrock | AWS | Hosted foundation models (Claude, Llama) | ✅ Yes (API within AWS) | ⚠️ Limited (fine-tuning only) |
| Google Vertex AI | GCP | Training + Inference on GCP | ✅ Yes (within GCP) | ✅ Custom containers supported |
| Azure ML | Azure | Training + Inference on Azure | ✅ Yes (within Azure) | ✅ Custom containers supported |
| Azure OpenAI | Azure | Hosted GPT models on Azure | ✅ Yes (API within Azure) | ⚠️ Limited customization |
Why attractive: Compliance-friendly (data stays in your VPC), partially managed, pay-per-use, quick start.
The hidden reality: You still need platform engineers to manage endpoints, optimize costs, handle multi-account setups, and build internal abstractions. Most teams discover they've built a platform team managing cloud services—then need to rebuild to migrate to self-hosted as scale/cost demands change.
Why This Is 10x Harder Than Application Deployment
If you've ever deployed a web application to production, you might be thinking: "How hard can deploying a model really be? It's just another service."
Let me show you why AI infrastructure is a completely different beast:
| Aspect | Web Application | ML Model |
|---|---|---|
| Runtime | Node.js, Python (standard versions) | PyTorch + CUDA + cuDNN + Python + dozens of pip packages (all exact versions) |
| Resources | Modest RAM, fractional CPU | Large GPU RAM, multiple CPUs, specific GPU models (different GPUs have different capabilities) |
| Latency | Moderate latency acceptable | Low latency critical (especially for real-time apps) |
| Monthly Cost | Low cost for small apps | Significant GPU costs (must optimize aggressively) |
| State | Stateless (easy horizontal scaling) | Model weights in GPU memory (expensive cold starts) |
| Dependencies | npm install or pip install | CUDA driver mismatch = model won't load. One wrong version breaks everything. |
When you deploy a web application, you specify your runtime version and you're done. With a model, you need PyTorch, which requires a specific CUDA version, which requires a specific cuDNN version, which requires a specific Python version, plus dozens of other pip packages—all at exact versions. Get one wrong and your model silently falls back to CPU or just crashes.
Web applications are stateless. You can spin up ten instances, put a load balancer in front, and call it a day. ML models load multi-gigabyte weight files into GPU memory. Cold starts aren't measured in milliseconds—they're measured in seconds. Horizontal scaling isn't simple because each new instance needs to load the entire model into GPU memory.
Real-World Pain Points (What Teams Face Today)
Let me walk you through some scenarios that happen every day in companies trying to deploy ML models.
The Deployment Bottleneck
Data Scientist: "The model is ready! We're hitting excellent accuracy. This is ready for production!"
DevOps Team: "Okay, we need to build a custom Docker container, configure GPU node selectors in Kubernetes, set up the ingress, configure monitoring, write health checks... give us a few weeks."
CEO (overhearing): "Weeks? We're deploying a file. How does that take weeks?"
And that's the reality. Models sit in Jupyter notebooks for months, not because they don't work, but because the deployment infrastructure doesn't exist.
The Lost Model
A senior data scientist leaves your company. No problem, right?
Except there's a model running in production—let's call it v3—and nobody knows how to recreate it. The training code was in a personal Jupyter notebook that's now deleted. There's no model registry, no version history, no documentation about what data was used or how it was trained.
Now you're spending months trying to reverse-engineer the model from inference logs and scattered Slack messages, hoping you can reproduce the same accuracy.
The Latency Mystery
In the data scientist's Jupyter notebook, the model inference is fast. Perfect! You deploy to production, and suddenly latency is through the roof. Users are complaining.
The debugging journey begins. You check the model code—it's identical to Jupyter. You check the GPU—it says it's running on GPU. Finally, after weeks of investigation, you discover the root cause: a missing CUDA environment variable. The model has been silently falling back to CPU the entire time.
The worst part? There was no error message. It just quietly degraded.
This is where AI agents transform operations. An SRE agent detects the CPU fallback, identifies the missing environment variable, and suggests the fix—in seconds instead of weeks. These agents are already handling similar debugging tasks in production today.
The Framework Jungle
Your company has four data science teams. Team A uses PyTorch. Team B uses TensorFlow. Team C has custom ONNX models. Team D uses scikit-learn and doesn't even need GPUs.
The platform team tries to build infrastructure that supports all of them, but each framework has different requirements, different deployment patterns, different optimization strategies. In the end, each team builds their own deployment pipeline. Zero reuse. Maximum chaos.
The Path Forward: What Teams Should Do Today
For Startups (Few models deployed)
Recommendation: Use cloud managed services, don't build infrastructure yet.
Options:
- AWS SageMaker Serverless Inference
- Google Vertex AI Prediction
- Azure ML Managed Endpoints
Trade-off: Higher cost per inference, but zero operational burden.
When to graduate: When cloud managed service costs become significant and you need more control over GPU infrastructure.
For Growing Teams (Multiple models in production)
Recommendation: Build your own AI infrastructure. The cost and limitations of cloud managed services become too high.
What to build:
- Kubernetes cluster with GPU node pools
- Model serving (KServe, vLLM, or Triton)
- Model registry (MLflow or custom)
- Basic monitoring (Prometheus + Grafana)
Team needed: Platform engineers (or 1-2 engineers leveraging emerging AI agent tools for automation)
Timeline: Months to build, more months to stabilize (AI agents can reduce setup time by automating configuration)
For Enterprises (Many models deployed)
Recommendation: Build a full internal AI platform. This is a multi-year investment.
Why enterprises need this:
- Compliance: HIPAA, SOX, FedRAMP, GDPR - data cannot leave your infrastructure
- Cost at scale: At 50+ models in production, owned infrastructure is far cheaper than per-API-call pricing
- Ownership & control: Complete control over GPU resources, security policies, data residency, and infrastructure evolution
Components to build:
- Custom GPU optimization and scheduling
- Multi-framework model serving
- Advanced monitoring and cost attribution
- Self-service portal for data scientists
- Integration with cloud services for hybrid workloads
Team needed: Dedicated platform engineering team
Investment: Significant upfront cost, but pays off through GPU utilization savings and productivity gains
The Vision: Where AI Infrastructure is Heading
The Missing Piece (What Doesn't Exist Yet)
Think back to 2010. Deploying a web application meant renting a server, configuring Apache, setting up databases, managing dependencies, writing deployment scripts. It took days or weeks.
Then Heroku came along and changed everything:
git push origin main
# [remote] Building with Buildpack...
# [remote] Detecting runtime, installing dependencies...
# [remote] ✅ Deployed to https://my-app.herokuapp.com
Minutes. Zero complexity. The platform handled everything.
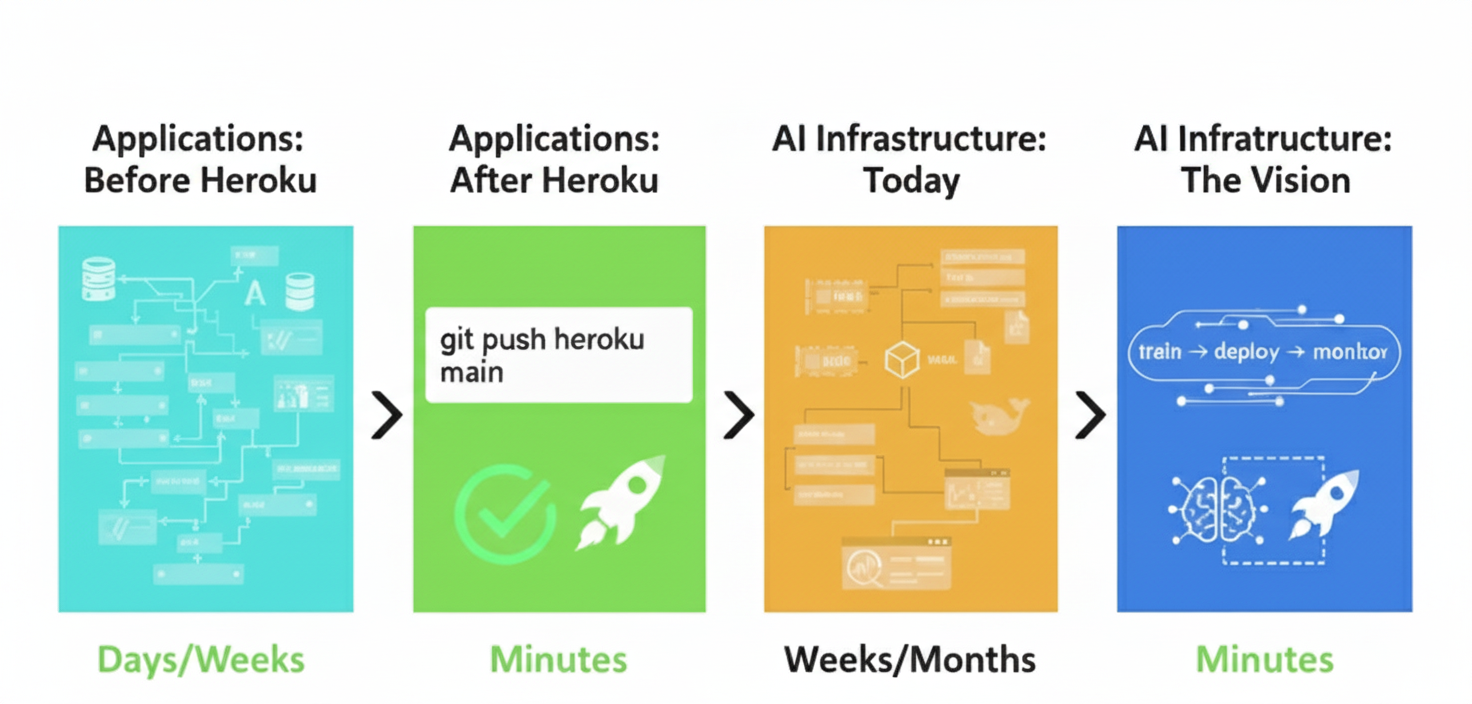
That revolution HAS happened for hosted platforms (Modal, Replicate, Baseten, Together AI)—but NOT for enterprises running on their own infrastructure.
If you want to deploy a model on your own Kubernetes cluster, your AWS account, or your on-premise datacenter, this simple experience doesn't exist:
model push my-llm.pkl
# ❌ Command not found
Instead, you're stuck with a manual process: write a Dockerfile, build the container, push to a registry, write Kubernetes YAML, configure GPU scheduling, set up ingress and DNS, configure monitoring, deploy to cluster, test endpoints, debug why it's not working. Days to weeks of work. Requires DevOps and SRE expertise.
What's missing for self-hosted infrastructure:
- Standardized model packaging (like Docker did for apps)
- Automatic GPU optimization
- Cost-aware scaling by default
- Unified API that works across your own Kubernetes cluster, your AWS/GCP/Azure account, or on-premise
- Developer-friendly CLI that just works
- Built-in model versioning and rollback
The tools exist in fragments, but nobody has assembled them into a cohesive platform that makes building AI infrastructure on your own cluster as simple as hosted platforms.
What Would an Ideal AI Platform Look Like?
Let's imagine we could solve all the complexity we just explored. What would the ideal AI infrastructure platform look like? What would it feel like to use?
The Dream Data Scientist Experience:
The complete workflow—from training a model on your proprietary data to deploying it in production—should be as simple as deploying a web application.
Today, data scientists face a trade-off:
- Use hosted platforms (Fireworks AI, Together AI, Baseten) → simple but your data leaves your infrastructure
- Build everything yourself → full control but requires months of infrastructure work
What if there was a third option? Train and deploy on your own infrastructure with the simplicity of hosted platforms.
💡 Click to see the complete workflow example (train → deploy → monitor)
# ═══════════════════════════════════════════════
# STEP 1: TRAIN YOUR MODEL (Fine-tune Llama 3 8B)
# ═══════════════════════════════════════════════
astroctl ai train \
--model llama-3-8b \
--data s3://my-bucket/proprietary-healthcare-data/ \
--output s3://my-bucket/models/llama-3-healthcare
# 🤖 Nova: Analyzing training job...
#
# Training Requirements:
# • Model: Llama 3 8B (15.2GB params)
# • Dataset: 50GB (10M examples)
# • Task: Text generation fine-tuning
#
# What's your priority? cost/speed/balanced: balanced
#
# ✨ Generating training plan...
#
# ╔════════════════════════════════════════════╗
# ║ Recommended Training Plan ║
# ╠════════════════════════════════════════════╣
# ║ GPUs: 8× A100 40GB ║
# ║ Framework: PyTorch + DeepSpeed ZeRO-3 ║
# ║ Strategy: Fully Sharded Data Parallel ║
# ║ Cluster: Your AWS us-east-1 (EKS) ║
# ║ ║
# ║ 💰 Estimated Cost: $160-320 one-time ║
# ║ (depends on dataset size, epochs) ║
# ║ ║
# ║ Why: A100 40GB perfect for 8B + FSDP; ║
# ║ 8 GPUs balance speed and cost ║
# ║ Data stays in your VPC ║
# ╚════════════════════════════════════════════╝
#
# Approve estimated cost? [Y/n]: Y
#
# ✅ Approved! Starting training...
# ⏳ Provisioning 8× A100 GPUs...
# ✅ GPUs ready, loading data from S3...
# ✅ Starting distributed training (DeepSpeed ZeRO-3)...
#
# [Live training progress]
# Epoch 1/3 │ Loss: 2.341 → 1.892 │ GPU: 94% │ Cost: $42
# Epoch 2/3 │ Loss: 1.534 → 1.287 │ GPU: 93% │ Cost: $98
# Epoch 3/3 │ Loss: 1.042 → 0.891 │ GPU: 92% │ Cost: $156
#
# ✅ Training complete!
# Model saved: s3://my-bucket/models/llama-3-healthcare/
# Checkpoints: s3://my-bucket/models/llama-3-healthcare/checkpoints/
# GPUs released (no longer billed)
#
# Final cost: $158
# ═══════════════════════════════════════════════
# STEP 2: DEPLOY YOUR TRAINED MODEL
# ═══════════════════════════════════════════════
astroctl ai model deploy s3://my-bucket/models/llama-3-healthcare/
# 🤖 Nova: Found your trained model. Analyzing...
#
# Model Details:
# • Model: Llama 3 8B (fine-tuned)
# • Framework: PyTorch (safetensors)
# • Size: 15.2 GB
# • Training completed: 2 hours ago
#
# What's your priority? cost/performance/balanced: cost
# Expected traffic (rps): 20
# Latency requirement (ms): 500
# Preferred region: us-east-1
#
# ✨ Generating deployment plan...
#
# ╔════════════════════════════════════════════╗
# ║ Recommended Deployment Plan ║
# ╠════════════════════════════════════════════╣
# ║ Runtime: vLLM 0.6.0 (optimized for 8B) ║
# ║ GPUs: 2× A10 (24GB each) ║
# ║ Scaling: Serverless 0→10 replicas ║
# ║ Platform: Your EKS cluster (us-east-1) ║
# ║ ║
# ║ 💰 Cost: $891/month recurring ║
# ║ GPU: $600 │ EKS: $73 │ LB: $18 ║
# ║ Storage: $100 │ Net: $100 ║
# ║ ║
# ║ Performance: ║
# ║ P95 latency: 245ms (meets 500ms SLO) ║
# ║ Max throughput: 200 req/s ║
# ║ Scale-to-zero when idle: Yes ║
# ║ ║
# ║ Why: A10 fits your 8B model perfectly; ║
# ║ serverless minimizes idle GPU costs; ║
# ║ EKS control plane shared w/ workloads ║
# ╚════════════════════════════════════════════╝
#
# Approve $891/month? [Y/n]: Y
#
# ✅ Approved! Deploying...
# ⏳ Creating KServe InferenceService (~8 min)...
# ✅ Model loaded, running health checks...
#
# ✅ Deployment Ready!
#
# Endpoint: https://ai.yourcompany.com/v1/chat/completions
# API Key: sk-prod-*** [saved to ~/.astropulse/keys]
#
# Quick test:
# curl https://ai.yourcompany.com/v1/chat/completions \
# -H "Authorization: Bearer sk-prod-***" \
# -d '{"model":"llama-3-healthcare","messages":[...]}'
# ═══════════════════════════════════════════════
# STEP 3: CREATE API KEYS (Access Control)
# ═══════════════════════════════════════════════
# Multi-tenant key management with lifecycle operations: create, revoke, rotate, delete
astroctl ai keys create \
--name "healthcare-app-production" \
--model llama-3-healthcare \
--rate-limit 1000/hour \
--tenant acme-health
# 🔐 API Key created: sk-prod-abc123xyz***
# Tenant: acme-health
# Permissions:
# • Model access: llama-3-healthcare
# • Rate limit: 1000 requests/hour
# • Scope: production
# • Expires: Never (rotate regularly recommended)
#
# Key saved to: ~/.astropulse/keys/healthcare-app-production
# Manage keys: astroctl ai keys [list|revoke|rotate|delete]
# ═══════════════════════════════════════════════
# STEP 4: MONITOR IN PRODUCTION
# ═══════════════════════════════════════════════
astroctl ai metrics llama-3-healthcare
# Current Stats:
# Status: Ready (running 12 days)
# Replicas: 3 / 10 (autoscaling based on load)
# Requests/s: 42 (peak: 87 yesterday)
# Latency P95: 223ms (well within 500ms SLO)
# GPU Util: 72% average
# Cost/month: $785 actual (vs $800 estimated)
# Uptime: 99.97%
#
# ✅ All systems healthy
The key insight: Many excellent platforms exist for AI workloads:
- Hosted training/inference: Fireworks AI, Together AI, Baseten (great for quick start, but your data leaves your control)
- Fine-tuning platforms: Oumi, Predibase (specialized for fine-tuning)
- Training frameworks: Modal, Anyscale (powerful but complex)
The gap: No platform yet solves training AND deploying models on your own infrastructure (your Kubernetes cluster, your cloud account, your on-premise network) with the same simplicity as hosted platforms—while maintaining complete ownership, control, and data sovereignty.
What Would the Ideal Platform Look Like?
| Aspect | Hosted Platforms | Cloud-Managed (SageMaker, Bedrock, Vertex) | Build It Yourself | The Vision |
|---|---|---|---|---|
| Data sovereignty | ❌ Data leaves your network | ⚠️ Stays in cloud VPC | ✅ Your infrastructure | ✅ Your choice |
| Ease of use | ✅ Simple (minutes) | ⚠️ Moderate (cloud-specific) | ❌ Complex (weeks/months) | ✅ Simple (minutes) |
| Time to deploy | Minutes | Hours to days | Weeks to months | Minutes |
| Training + Inference | ⚠️ Usually separate tools | ⚠️ Provider-specific | ✅ Full control (if you build it) | ✅ Unified workflow |
| Customization | ❌ Limited | ⚠️ Moderate | ✅ Full control | ✅ Full control |
| Operational burden | None | ⚠️ Some (cloud-specific) | ❌ High (requires platform team) | ✅ Low (AI-powered) |
| Vendor lock-in | ❌ High | ❌ High (per cloud provider) | ✅ None | ✅ None |
| Cost optimization | ❌ Per-token pricing | ⚠️ Cloud pricing | ✅ Optimized (if done right) | ✅ Automatic + flexible |
| Compliance-ready | ❌ Depends on vendor | ✅ Cloud compliance (HIPAA, SOC2) | ✅ Complete control | ✅ Built-in governance |
What would make this simple: A unified platform that gives flexibility to deploy anywhere AND evolve over time:
- Start with Bedrock/Azure OpenAI for quick wins (general-purpose LLMs)
- Add SageMaker/Vertex AI when you need custom training (but don't want to manage clusters yet)
- Migrate to self-hosted Kubernetes as you scale (for cost optimization and control)
- Maintain a single interface throughout this journey—no rewrites when you migrate
The goal: deploy the right workload to the right place, and evolve your infrastructure strategy over time without rebuilding your entire deployment pipeline.
Why this matters: Most teams start with cloud-managed services and eventually migrate to self-hosted. A unified platform means you can start simple and progressively take more control—without throwing away months of platform engineering work.
The complete data scientist workflow:
- Train on your data (stays in your VPC) →
astroctl ai train - Deploy your trained model (on your cluster) →
astroctl ai model deploy - Monitor in production (your observability stack) →
astroctl ai metrics
All powered by AI agents like Nova that automatically configure distributed training, select optimal GPUs, estimate costs, and handle infrastructure complexity.
Platform Requirements:
One Command Deploy
No Docker, no Kubernetes YAML, no configuration files. Just: deploy model.pkl
Auto-Detection
Automatically detect framework, dependencies, Python version, CUDA requirements
Fractional GPUs
Share GPUs across models. Pay for what you use, not whole instances
Scale to Zero
Automatically scale down to zero when idle. Scale up in < 2 seconds
Instant APIs
Auto-generate REST/gRPC endpoints with DNS and TLS
AI-Powered Operations
AI agents like Nova help debug issues, optimize performance, reduce operational toil
Cost Optimization
Smart scheduling, fractional allocation, scale-to-zero by default
Enterprise Control
Run on your Kubernetes, your datacenter, your compliance requirements
Making It Simple: The Path to Enterprise AI Platforms
The building blocks exist today: KServe, vLLM, Triton, Kubernetes GPU scheduling, MLflow, Prometheus/Grafana. The challenge? They're scattered across dozens of platforms. Setting them up and maintaining them requires significant expertise. No unified experience brings it all together simply.
What would make it simple:
A platform that lets data scientists own the entire workflow without DevOps expertise. Training on proprietary data to production deployment—in minutes, not weeks. GPU costs optimized automatically (ephemeral provisioning for training, intelligent scaling for inference). Distributed training setup automatic (DeepSpeed ZeRO-3, PyTorch FSDP configured by AI to shard models across GPUs). Model versioning and rollback just work.
AI-powered operations where agents debug issues, optimize performance, reduce toil. Instead of hours troubleshooting failed deployments, an AI agent analyzes logs, identifies issues, suggests fixes.
Most importantly: a platform you run on your own infrastructure—your Kubernetes cluster, your cloud account, or your on-premise network—meeting your compliance requirements.
The AI Agent Revolution: Changing the Economics
We're already seeing specialized AI agents handle traditional engineering roles—SRE agents debugging production issues, platform agents generating infrastructure-as-code, DevOps agents automating deployments. Companies like Cognition (Devin), Sweep, and others are deploying these agents in production today.
For AI infrastructure, this is transformative. The traditional 5-10 person platform team (SREs, platform engineers, DevOps, FinOps, security) can become 1-2 engineers + AI agents. The future architecture: specialized small models (fine-tuned on YOUR data for business logic) + AI agents (automating infrastructure operations). This combination delivers better accuracy than foundation models, lower costs, data sovereignty—making self-hosted infrastructure practical for companies of all sizes.
The shift: AI infrastructure is no longer "enterprises only." Specialized models + AI agents make it accessible to any company that values data sovereignty and cost control.
The Reality: Building This is a Journey
Building a complete AI infrastructure platform is a journey. No platform has everything on day one. Some capabilities—like deep cloud provider integrations—take time to build. But for enterprises running government clusters, on-premise datacenters, or air-gapped environments, having a solid foundation on their infrastructure is more valuable than every cloud integration.
The opportunity: taking the building blocks that exist today and assembling them into something that makes AI infrastructure accessible to every enterprise. Start with core capabilities—model deployment, GPU management, monitoring—and grow from there.
Just like internal developer platforms democratized application deployment, AI agents are democratizing AI infrastructure.
The Future: AI Agents Democratize Infrastructure
The opportunity is clear: enterprises want to run AI infrastructure in their own cloud accounts or on-premise networks with the same simplicity that managed platforms provide—without sacrificing ownership or compliance.
Why this is becoming practical: We're entering an era where AI agents are beginning to handle the operational burden that made managed platforms the only viable option. Early agents already tackle debugging, optimization, and distributed training configuration—tasks that previously required dedicated platform teams.
Imagine this future: building AI infrastructure on your own Kubernetes cluster is as simple as deploying applications. Data scientists can train models on their proprietary data and deploy to production—all without touching Kubernetes YAML or Docker files. "Train → Deploy → Monitor" becomes as simple as "push code → get URL"—but running on infrastructure you own and control, with AI agents as your platform engineering team.
This isn't a distant dream. All the building blocks exist today. GPU scheduling works. Model serving frameworks work. Kubernetes works. AI agents can already automate operations. The opportunity is assembling them into something cohesive and simple.
The vision: Enable every enterprise to run their own AI infrastructure platform, just like they run internal developer platforms today. Full ownership, control, and data sovereignty—without operational complexity or large platform teams.
This is especially valuable for enterprises running government clusters, on-premise datacenters, or air-gapped environments where cloud provider integrations aren't the primary concern. These organizations need a solid foundation that runs on their infrastructure first, with additional capabilities growing over time.
The shift: From choosing between control (self-hosted but complex) or simplicity (managed but lose ownership) to having both—control AND simplicity—because AI agents handle the operational complexity.
The future of enterprise AI isn't choosing between managed platforms or building from scratch.
It's building your own with AI-powered operations—full functionality, cost control, ownership, and compliance—without compromise.
This future is inevitable—someone will make AI infrastructure this simple. The opportunity is clear, the building blocks exist, and the market desperately needs it.
What this could look like:
💡 Click to see the vision: Simple commands for complex AI infrastructure
# Train your model on YOUR data (stays in YOUR VPC)
astroctl ai train --model llama-3-8b --data s3://your-data/
# Deploy your trained model (on YOUR infrastructure)
astroctl ai model deploy s3://your-models/llama-3-healthcare/
# Monitor in production (YOUR observability)
astroctl ai metrics llama-3-healthcare
Everything—distributed training setup (DeepSpeed ZeRO-3 or PyTorch FSDP for sharding models across GPUs), GPU selection, cost estimation, approval workflows, deployment orchestration, monitoring—handled automatically, powered by AI agents that understand your infrastructure and optimize for your goals.
The key is starting with the right foundation: proven open-source technologies (KServe, durable workflow orchestration, DeepSpeed/FSDP, supply chain security tools) assembled to work seamlessly together.
These are the problems we're exploring at AstroPulse—particularly for enterprises in government, healthcare, and finance where data sovereignty is non-negotiable.